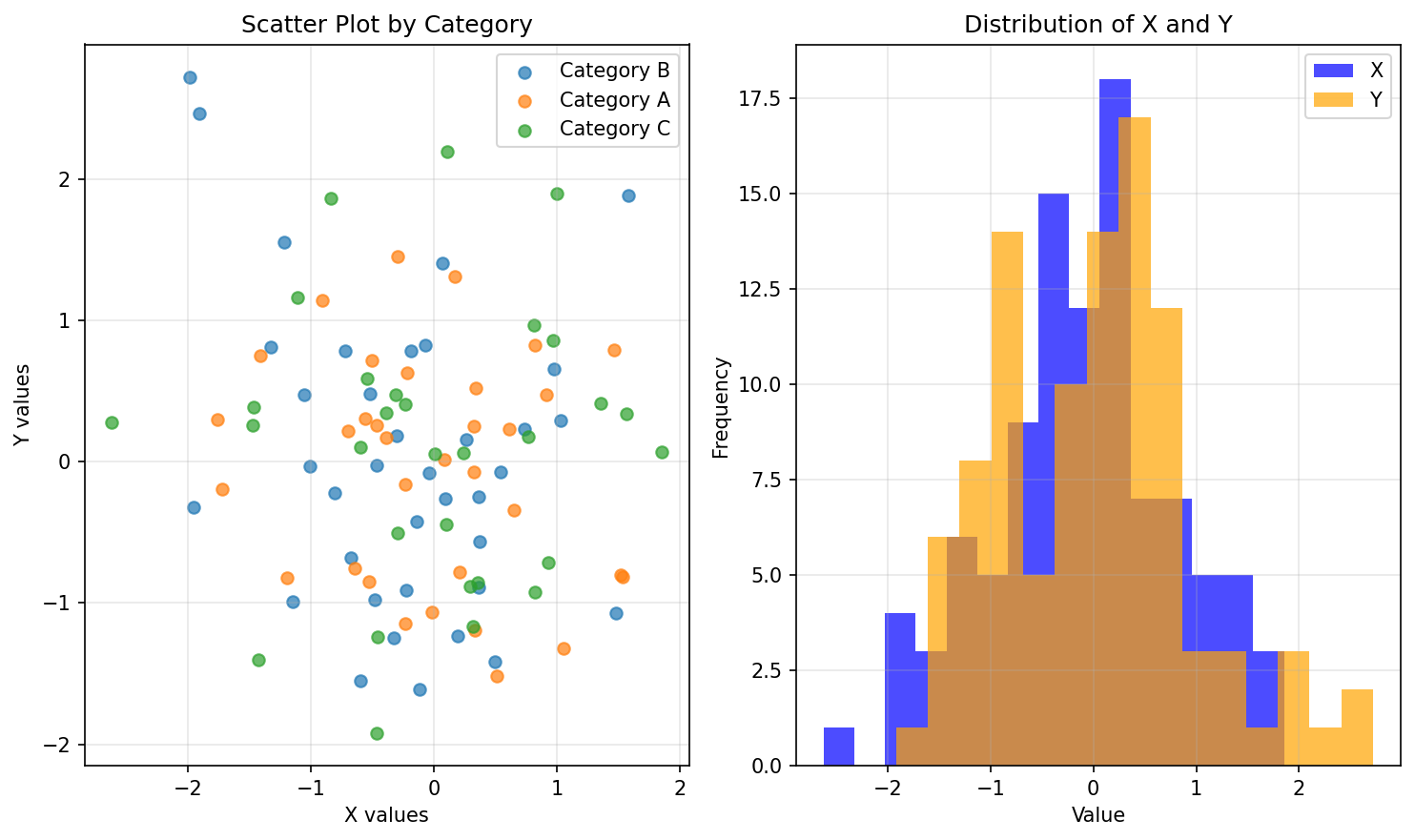
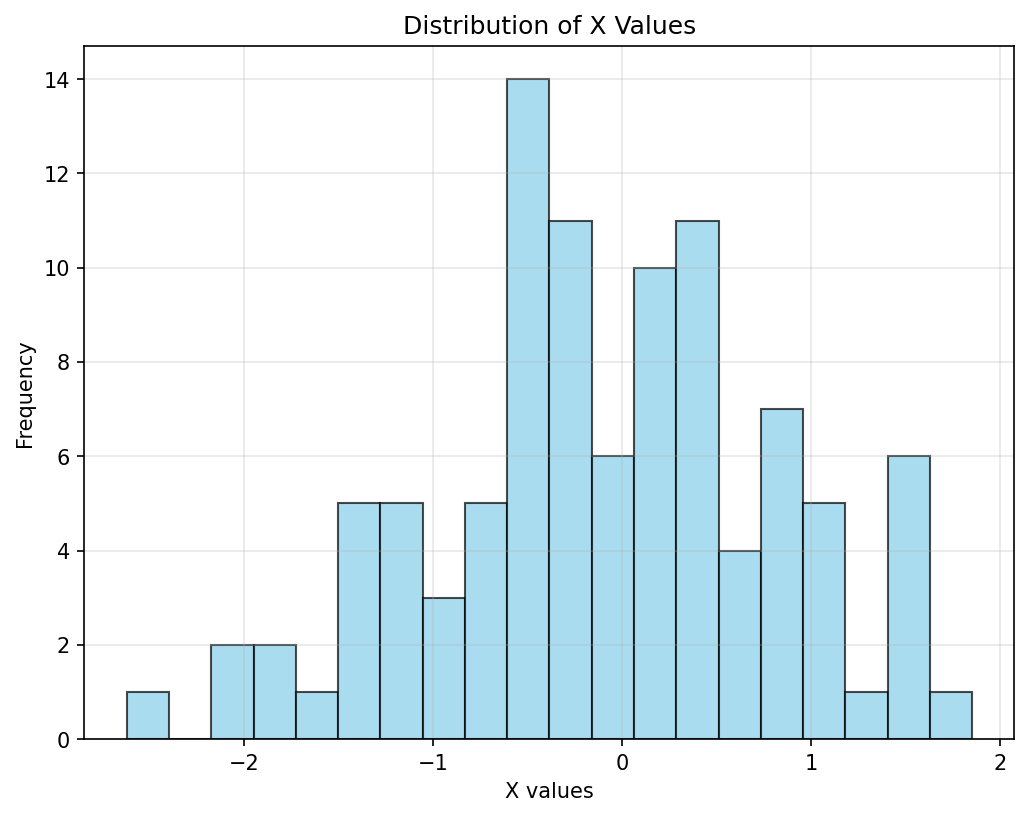
▼ code
▼ output
▶ uv-logs
|
Cell: generate_data | deps: numpy, pandas | 1.63s
|
Raw
import numpy as np
import pandas as pd
# Set seed for reproducibility
np.random.seed(42)
# Generate sample data
n_points = 100
data = pd.DataFrame({
'x': np.random.normal(0, 1, n_points),
'y': np.random.normal(0, 1, n_points),
'category': np.random.choice(['A', 'B', 'C'], n_points)
})
print(f"Generated {len(data)} data points")
print("\nFirst 5 rows:")
print(data.head())
print(f"\nData types:")
print(data.dtypes)
Generated 100 data points
First 5 rows:
x y category
0 0.496714 -1.415371 B
1 -0.138264 -0.420645 B
2 0.647689 -0.342715 A
3 1.523030 -0.802277 A
4 -0.234153 -0.161286 A
Data types:
x float64
y float64
category object
dtype: object
▶ UV Install Logs